Inicio de Hadoop
Tres partes:
- Preparar el HDFS
- Iniciar los demonios de Hadoop
- Preparación de los directorios de los usuarios
Preparación del HDFS
- Conéctate por ssh a la MV que hace el papel de NameNode/ResourceManager
- Conviértete en el usuario hdmaster (sudo su - hdmaster)
- Como usuario hdmaster, inicia el HDFS ejecutando, en el Namenode:
$ hdfs namenode -format
Al finalizar debería indicar: "INFO common.Storage: Storage directory /var/data/hadoop/hdfs/nn has been successfully formatted."
Inicio de los demonios
- En el NameNode/ResourceManager, como usuario hdmaster, inicia los demonio del HDFS y YARN ejecutando:
$ $HADOOP_PREFIX/sbin/hadoop-daemon.sh start namenode
$ $HADOOP_PREFIX/sbin/yarn-daemon.sh start resourcemanagerComprueba los ficheros de log en el directorio /var/log/hadoop del NameNode, para comprobar errores.
- Conéctate a la MV que hace el papel de DataNode1/NodeManager/CheckPointNode y (como usuario hdmaster) lanza los demonios correspondientes:
$ $HADOOP_PREFIX/sbin/hadoop-daemon.sh start datanode
$ $HADOOP_PREFIX/sbin/yarn-daemon.sh start nodemanager
$ $HADOOP_PREFIX/sbin/hadoop-daemon.sh start secondarynamenode
- Conéctate a la MV que hace el papel de DataNode2/NodeManagerJobHistoryServer y (como usuario hdmaster) lanza los demonios correspondientes:
$ $HADOOP_PREFIX/sbin/hadoop-daemon.sh start datanode
$ $HADOOP_PREFIX/sbin/yarn-daemon.sh start nodemanager
$ $HADOOP_PREFIX/sbin/mr-jobhistory-daemon.sh start historyserver
- Abre un navegador en tu PC y chequea las siguientes páginas
- http://namenode:50070 interfaz web del HDFS
- http://namenode:8088 interfaz web de YARN
- http://checkpointnode:50090 interfaz web del CheckPoint node
- http://jobhistoryserver:19888/ interfaz web del JobHistory server
- A través de esos interfazes, comprueba que todo está funcionando como debiera.
- IMPORTANTE: Desde la Wireless Eduroam, no vamos a tener acceso a estos puertos. Para poder acceder, puedes usar la siguiente solución:
- Abre en tu PC un proxy SOCKS al NameNode ejecutando el siguiente comando:
ssh -f -N -D localhost:1080 root@namenode
En tu navegador web, accede a las propiedades de red y especifica como proxy un servidor SOCKS v5, localhost puerto 1080, como se ve en la figura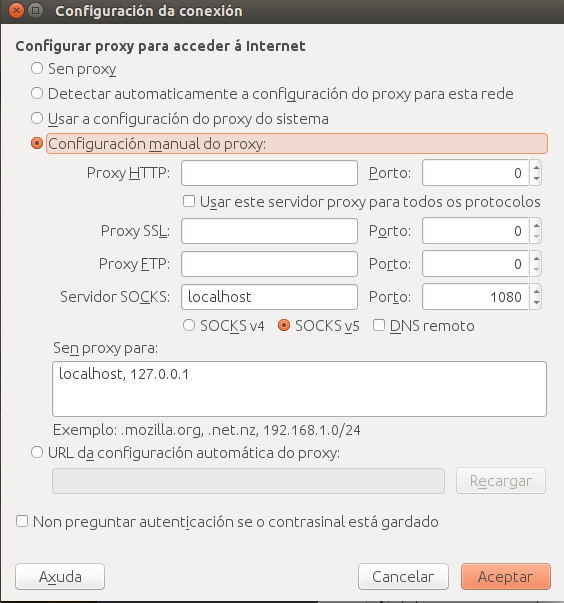
Cuando termines, recuerda quitar esta configuración del navegador.
- Abre en tu PC un proxy SOCKS al NameNode ejecutando el siguiente comando:
Otra forma de iniciar los demonios en los DataNodes/NodeManagers
Se pueden iniciar los demonios de los DataNodes/NodeManagers directamente desde el NameNode:
- En el fichero $HADOOP_PREFIX/etc/hadoop/slaves borra localhost y pon las IPs de los dos DataNodes/NodeManagers (una IP por línea).
- También desde el NameNode, inicia el demonio del HDFS y YARN en los DataNodes/nodemanagers (fijate en la s final de los comandos)
$ $HADOOP_PREFIX/sbin/hadoop-daemons.sh start datanode
$ $HADOOP_PREFIX/sbin/yarn-daemons.sh start nodemanager
Parada de los demonios
El proceso de parar los demonios es el inverso del seguido para iniciarlos, cambiando start por stop. (No los pares de momento, a menos que tengas que apagar las máquinas. Para evitar problemas, siempre que detengas las máquinas detén los demonios antes).
Prueba de un ejemplo
Como test de nuestra instalación, podemos ejecutar un ejemplo de MapReduce:
- Desde el NameNode, como usuario hdmaster, ejecuta lo siguiente
$ export YARN_EXAMPLES=$HADOOP_PREFIX/share/hadoop/mapreduce
$ yarn jar $YARN_EXAMPLES/hadoop-mapreduce-examples-2.7.*.jar pi 4 10Mientras se ejecuta, comprueba en el interfaz web de YARN la evolución. Al terminar, comprueba que se ha guardado información de la ejecución en el JobHistory server.